
This post describes how Pytolab was designed to process Tweets related to the 2012 French presidential election in real-time. This post also goes over some of the statistics computed over a period of nine months.
Note: I presented this project at EuroSciPy 2012: abstract.
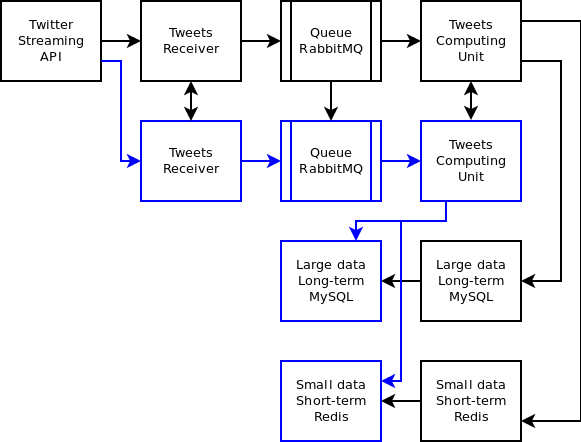
Architecture
The posts are received from the Twitter streaming API and sent to a messaging exchange. The posts are read from the messaging queue and processed by the computing unit. Most frequently accessed and updated data like statistics is stored in an in-memory DB (Redis), larger long-term data is stored in MySQL on-disk. See the diagram below.

Tweets receiver
The Twitter streaming API filter feature is used here to receive the tweets we are interested in: Tweets referring to at least one of the candidates. The helper library Tweepy facilitates that task.
First thing we do is set up a stream listener. We get a listener instance, set the callback to be called when a new post arrives and finally get a stream instance by passing our listener instance to it. We will see next how those different objects are defined.
def setup_stream_listener(self):
"""
Setup Twitter API streaming listener
"""
listener = Listener()
listener.set_callback(self.mq.producer.publish)
self.stream = tweepy.Stream(
self.config.get('twitter', 'userid'),
self.config.get('twitter', 'password'),
listener,
timeout=3600
)
Note: We use ConfigParser for the configuration file management.
The Listener class is derived from the tweepy.StreamListener class. We overwrite some of the methods to indicate what to do when a new post arrives or when an error is detected.
class Listener(tweepy.StreamListener):
def on_status(self, status):
# Do things with the post received. Post is the status object.
...
def on_error(self, status_code):
# If error thrown during streaming.
...
def on_timeout(self):
# If no post received for too long
...
def on_limit(self, track):
# If too many posts match our filter criteria and only a subset is
# sent to us
...
def on_delete(self, status_id, user_id):
# When a delete notice arrives for a post.
...
def set_callback(self, callback):
# Pass callback to call when a new post arrives
self.callback = callback
We need to add few lines of code to the on_status method. We parse what we are interested in and publish the data to our messaging queue. We filter out the posts written by an author whose language is not French. The callback is our messaging queue producer publish method.
def on_status(self, status):
if status.author.lang == 'fr':
message = {
'author_name': status.author.screen_name,
'author_id': status.author.id,
'id': status.id,
'text': status.text,
'retweeted': status.retweeted,
'coordinates': status.coordinates,
'time': int(time.time())}
self.callback(json.dumps(message), 'posts')
We will see later how the messaging queue producer and consumer are built.
There is one more thing we need to do: setting up our streaming filter so we start receiving posts from Twitter we are interested in. We have a list of presidential candidates in the list self.persons. We build a list of names and start listening for them. The call to stream.filter is blocking and the method on_status of the listener class is called each time a new post arrives.
Keep in mind that the streaming filter returns at most 1% of all posts processed by Twitter. This means that if the posts referring to our candidates represent more than 1% of all posts on Twitter at instant t, then the number of posts will be capped at 1%. We encountered this case only twice: during the first round results and during the second round results. We lost less than 10% of the posts when that situation happened. How do you make sure this does not happen? You will have to subscribe to the complete stream which is provided by some Twitter partners like DataSift and Gnip. Those solutions are not cheap.
Note that we are catching all exceptions. There is no guarantee that you will get continuous streaming with no errors so catching all exceptions is important here.
def stream_filter(self):
track_list = [data.normalize(p['name']) for p in self.persons]
while True:
try:
self.stream.filter(track=track_list)
except Exception:
logging.exception('stream filter')
time.sleep(10)
Some examples of errors I saw in the past:
File "/usr/local/lib/python2.6/dist-packages/tweepy-1.7.1-py2.6.egg/tweepy/streaming.py", line 148, in _read_loop
c = resp.read(1)
...
File "/usr/lib/python2.6/httplib.py", line 518, in read
return self._read_chunked(amt)
File "/usr/lib/python2.6/httplib.py", line 561, in _read_chunked
raise IncompleteRead(''.join(value))
IncompleteRead: IncompleteRead(0 bytes read)
File "/usr/local/lib/python2.6/dist-packages/tweepy-1.7.1-py2.6.egg/tweepy/streaming.py", line 148, in _read_loop
c = resp.read(1)
...
File "/usr/lib/python2.6/ssl.py", line 96, in <lambda>
self.recv = lambda buflen=1024, flags=0: SSLSocket.recv(self, buflen, flags)
File "/usr/lib/python2.6/ssl.py", line 222, in recv
raise x
SSLError: The read operation timed out
File "/usr/local/lib/python2.6/dist-packages/tweepy-1.7.1-py2.6.egg/tweepy/streaming.py", line 148, in _read_loop
c = resp.read(1)
...
File "/usr/lib/python2.6/ssl.py", line 136, in read
return self._sslobj.read(len)
error: [Errno 104] Connection reset by peer
Let’s take a look at what happens when the method stream.filter is called. An HTTPS POST request is made using the following URL: https://stream.twitter.com/1/statuses/filter.json?delimited=length and the following body: track=candidate1, candidate2,… The stream of data is then read in a loop until there is an error.
Here is an example of a post content:
{
"in_reply_to_user_id": null,
"in_reply_to_status_id": null,
"text": "bla bla bla",
"favorited": false,
...
}
A more complete example: https://gist.github.com/900964.
The Tweepy library formats that data as a status object and passes it to the on_status method of the listener object.
Messaging queue
We are using RabbitMQ for our messaging system plus the Python helper library py-amqlib. An exchange is created to receive the posts and a consumer reads the messages from a queue. Those messages are processed by the computing unit. The advantage of using a messaging queue is we can handle a surge of posts.
First is the producer. We create a connection to the messaging server and get a channel from that connection. This channel is used to publish messages to the exchange.
class Producer(object):
def __init__(self, exchange_name, host, userid, password):
self.exchange_name = exchange_name
self.connection = amqp.Connection(
host=host, userid=userid, password=password, virtual_host="/",
insist=False)
self.channel = self.connection.channel()
Our publisher class has a publish method to send a message to the exchange. Messages marked as ‘persistent’ that are delivered to ‘durable’ queues will be logged to disk. We use the routing key ‘posts’ which will also be used when we create the queue to route the messages properly.
def publish(self, message, routing_key):
msg = amqp.Message(message)
msg.properties["content_type"] = "text/plain"
msg.properties["delivery_mode"] = 2
self.channel.basic_publish(exchange=self.exchange_name,
routing_key=routing_key,
msg=msg)
Next is the consumer. We also get a connection to the messaging server and get a channel from that connection.
class Consumer(object):
def __init__(self, host, userid, password):
self.connection = amqp.Connection(host=host, userid=userid,
password=password, virtual_host="/", insist=False)
self.channel = self.connection.channel()
We also have a method creating the queue and one passing the method to be called each time there is a message to be consumed in the queue.
DB interface
Before we go over the computing unit, let’s look at the DB interface we created to interface with the in-memory DB Redis and MySQL.
Regarding Redis, our interface is built on top of the helper library redis-py. It adds retries around DB commands.
We use the following Redis commands (complexity of the command is shown next to it):
- GET key – O(1)
- SET key – O(1)
- DELETE key – O(1)
- EXISTS key – O(1)
- INCR key – O(1)
- RPUSH key value – O(1)
- LSET key index value – O(N)
- LINDEX key index – O(N)
- LRANGE key start stop – O(S+N)
The key used to store posts is ‘post:’. We dump the json post data as the key’s value. For ease of access, we also have a Redis list per person and per hour with the following key: ‘person::posts:’. This list contains the post ids related to this person during that hour.
Regarding MySQL, our interface is built on top of the helper library MySQLdb.
Here is the method to execute a MySQL command. If the command throws an operational error or an internal error, we try to reconnect to the MySQL server. If it throws a SQL error, we retry multiple times before raising a DBError.
def mysql_command(self, cmd, sql, writer, *args):
retry = 0
while retries < self.cmd_retries:
try:
r = getattr(self.db_cursor, cmd)(sql, args)
if writer:
self.db_disk_posts.commit()
return r
else:
return self.db_cursor.fetchall()
except (MySQLdb.OperationalError, MySQLdb.InternalError):
self.log.error('MySQL cmd %s DB error', cmd)
# reconnect
self.setup_mysql_loop()
retry = 0
except MySQLdb.Error:
self.log.error('MySQL cmd %s sql %s failed', cmd, sql)
retry += 1
if retry < self.cmd_retries:
time.sleep(self.cmd_retry_wait)
except AttributeError:
self.log.error('MySQL cmd %s does not exist', cmd)
raise exceptions.DbError()
We keep smaller and more recent data in Redis. MySQL is used for larger and long-term data.
We added a thin layer on top of the Redis and MySQL commands to make the dual DB setup transparent. When we request some data, it is read from Redis and/or MySQL based on its age or type.

Computing unit
We define a method called when there is a message to read from the queue. When a post is received, we process it the following way:
- Filter out posts marked as fr language and containing common English words. In most cases, this is a post fully written in English and we need to bypass those.
- For each person, check if this post is really about that person and not something unrelated.
- Store post data in DB.
def process_post(self, post):
"""
Process post received from the message queue.
"""
# is this a post matching one or more persons?
post_add = False
# remove accents and lowercase everything
text = data.normalize(post['text']).lower()
...
# check post language
if data.get_text_language(text) == 'fr':
for person in self.persons:
# get person's first name, last name and nickname
names = data.get_names(person)
# check if the post is really about that person
...
if post_add:
# add post to db
self.db.set_post(int(post_id),
json.dumps(post))
# add post id to current hour
key = 'posts:%d' % (self.stats_last_update)
self.db.rpush(key, post_id)
else:
logging.debug('found english word in %s', text)
Filtering out unrelated messages is key here. For example, “Je vais en Hollande demain” (I am going to Holland tomorrow) is not about the presidential candidate “Hollande” but about the country “Holland”. Both are spelled the same way in French. We defined a list of words and rules per person to help filtering out the unrelated posts.
High availability
Each element above can be made highly-available with the use of an extra server. We can add one more server receiving the tweets in case the active one fails. We can detect this type of failure using a heartbeat between the active and the stand-by instance. RabbitMQ supports mirror queues. Redis and MySQL support a master/slave architecture.
Performance
During peak traffic (first round results for example), the bottleneck in our system was the Twitter streaming listener. The code reads the length of the post data byte per byte from the stream and then reads the post data using the length value. This is quite CPU intensive and we had to switch from a small instance (1 computing units) on Amazon EC2 to a large one (4 computing units) to read the posts in real-time during traffic peaks.
The messaging system we used (RabbitMQ) can handle way more than what we used it for so no issue on that side.
Here is some comparison between Redis and MySQL when it comes to storing data on a small EC2 instance.
Method:
– MySQL: insert into table for each value, final commit.
– Redis: SET command for each value. Redis persists changes to disk in the background.
Adding 10k posts:
– MySQL: 4.0 seconds.
– Redis: 2.6 seconds – 1.53x faster.
Adding 100k posts:
– MySQL: 42.0 seconds.
– Redis: 23.7 seconds – 1.77x faster.
Statistics
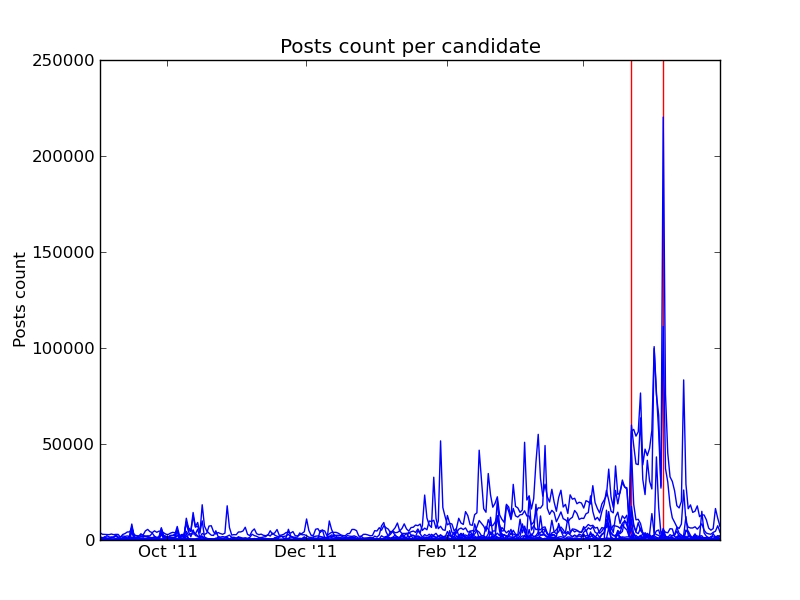
Over 8 millions tweets (8442728) related to the different candidates were analyzed by Pytolab from Sep 1st 2011 to June 1st 2012. Posts referring to at least one candidate were analyzed. This is different than the posts posted by the candidates themselves.
Here are some key dates from the presidential campaign:
- 1st round of the Socialist primaries: October 9th 2011
- 2nd round of the Socialist primaries: October 16th 2011
- 1st round of the presidential election: April 22nd 2012
- 2nd round of the presidential election: May 6th 2012
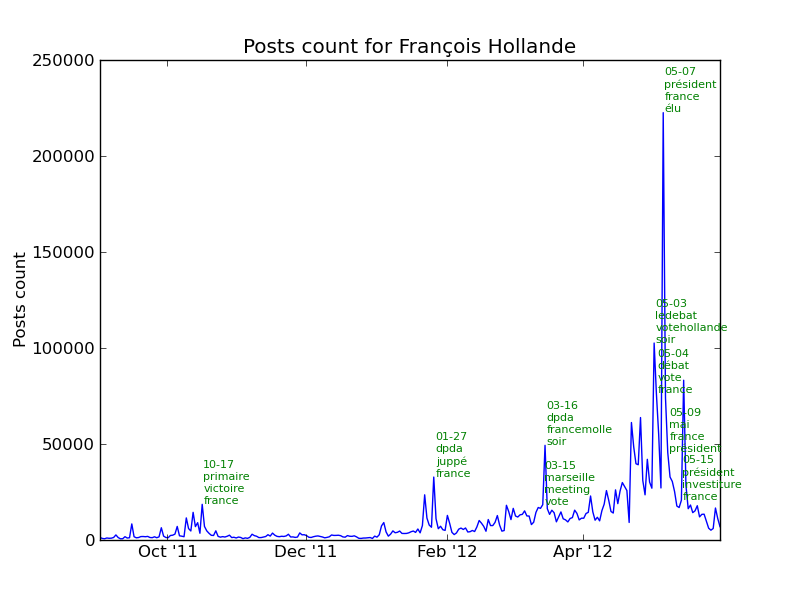
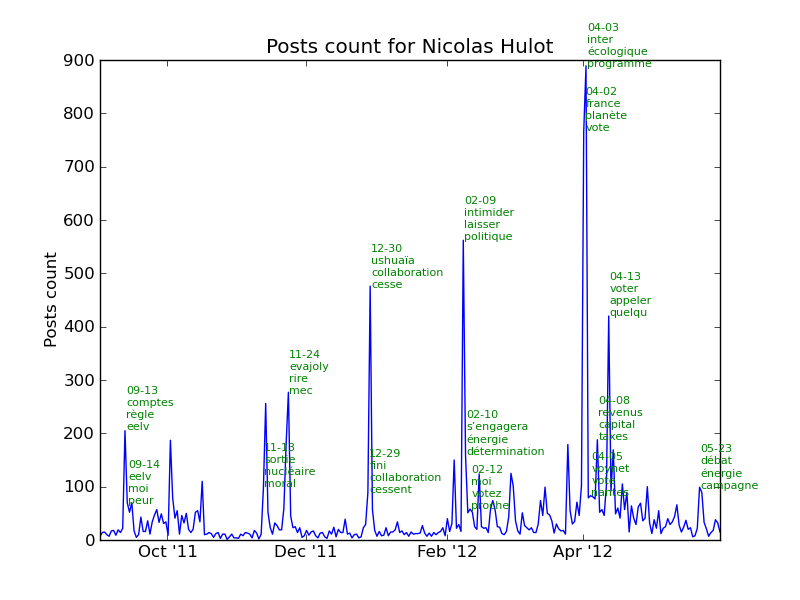
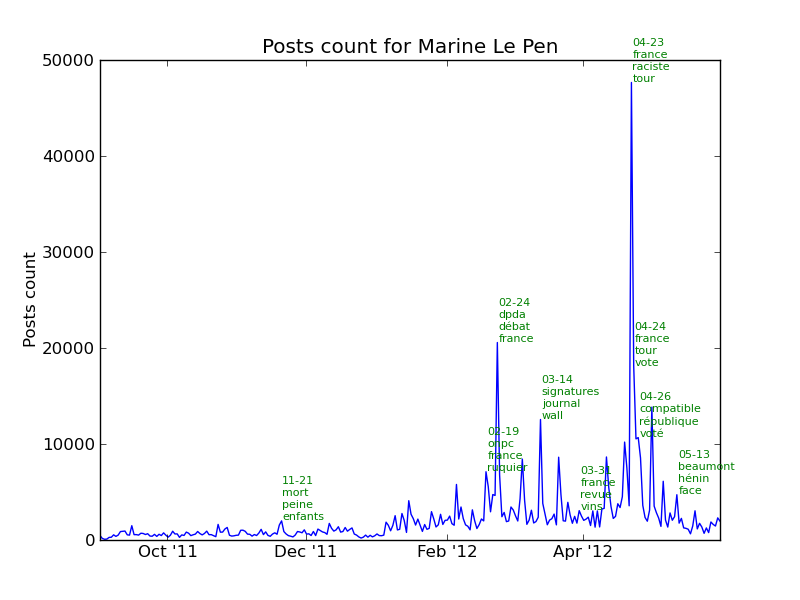
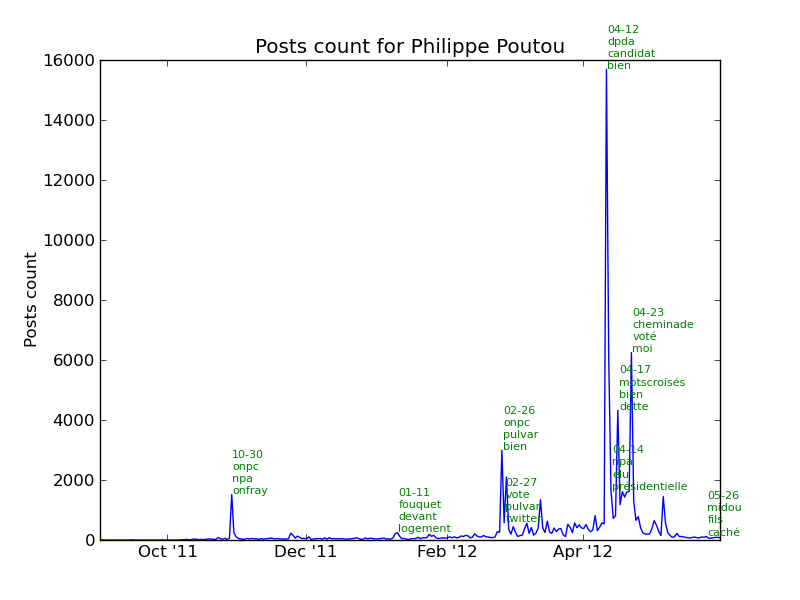
The following chart represents the number of posts per day for each candidate. The key dates described above are shown in red.
Here is the list of candidates we tracked:
List of candidates:
- Nathalie Arthaud
- Martine Aubry
- Jean-Michel Baylet
- François Bayrou
- Christine Boutin
- Nicolas Dupont Aignan
- François Hollande
- Nicolas Hulot
- Eva Joly
- Marine Le Pen
- Jean-Luc Mélenchon
- Arnaud Montebourg
- Philippe Poutou
- Ségolène Royal
- Nicolas Sarkozy
- Manuel Valls
- Dominique Villepin
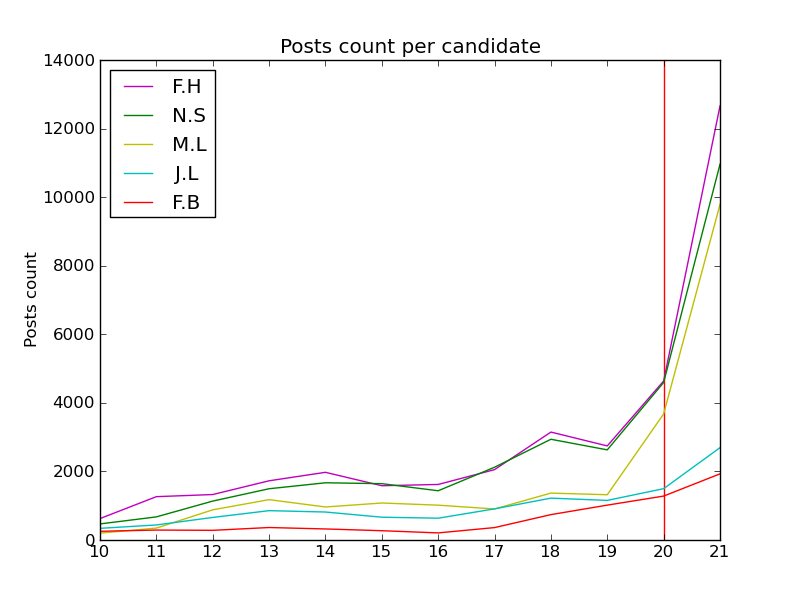
Here are the number of posts where each candidate’s name appears.

We noticed that Nicolas Sarkozy is referred in 41% of all posts we analyzed. François Hollande in 35% of all posts. There is no strong correlation between the number of posts per candidate and their polling result. The candidate with the most posts was the president at that time so it is expected to see those numbers.
| Posts count | Polls |
|---|---|
| Nicolas Sarkozy | François Hollande |
| François Hollande | Nicolas Sarkozy |
| François Bayrou | Marine Le Pen |
| Marine Le Pen | Jean-Luc Mélenchon |
| Jean-Luc Mélenchon | François Bayrou |
We noticed something interesting where the number of posts were matching the polls during the 11 hours preceding the first round results and during the 6 hours preceding the second round results.

Let’s look at the authors of the posts now. We counted 388628 different authors. 98.3% of authors posted less than 200 posts during those 9 months. That is less than 1 post per day. 0.7% of authors (2720) posted more than 500 posts and posted 45% of all posts.
The top 10 authors in number of posts are:
- sarkoactu: 26356
- bayrouactu: 26345
- Elysee_2012: 21076
- sarkozy_info: 18868
- FlashPresse: 16349
- Scrutin2012: 16229
- Eric_vds: 14667
- democrates: 14528
- akemoi: 14403
- blabalade: 14119
Here is the distribution of posts per hour for all posts over our period of 9 months:

If we look at the number of posts from “sarkoactu”. it is about 96 posts per day. Looking at the distribution of the posts per hour for that author, we notice that it is probably an automatic feed.
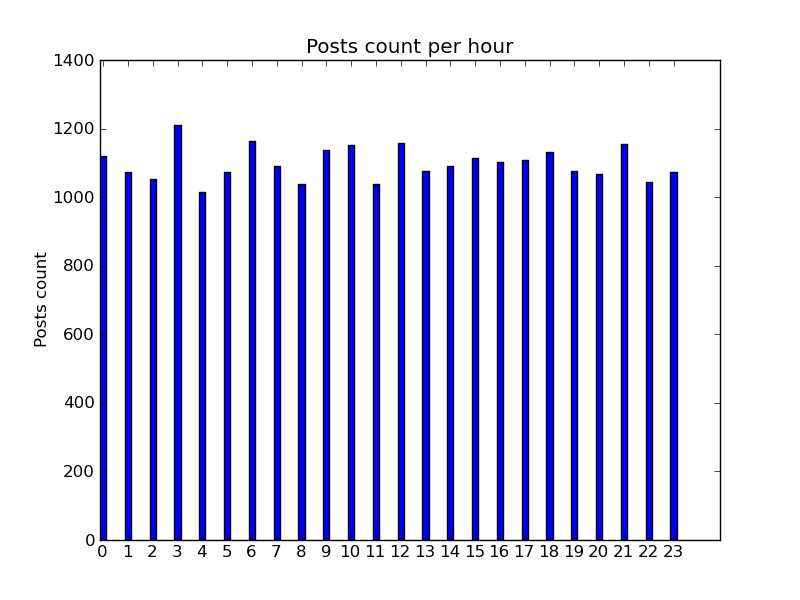
Looking at the full list of authors and their posts distribution per hour, we found out that 26 authors are probably automatic feeds and that they represent 215783 posts which is 2.5% of all posts.
Location metadata is attached to only 0.5% of all posts. In our case, this represents 40799 posts. There is not much difference between each candidate in regards to the post location. We do notice that the posts are issued mainly from French speaking countries: France, Belgium, Canada, Algeria, Tunisia… It makes sense as we analyzed posts written in French.
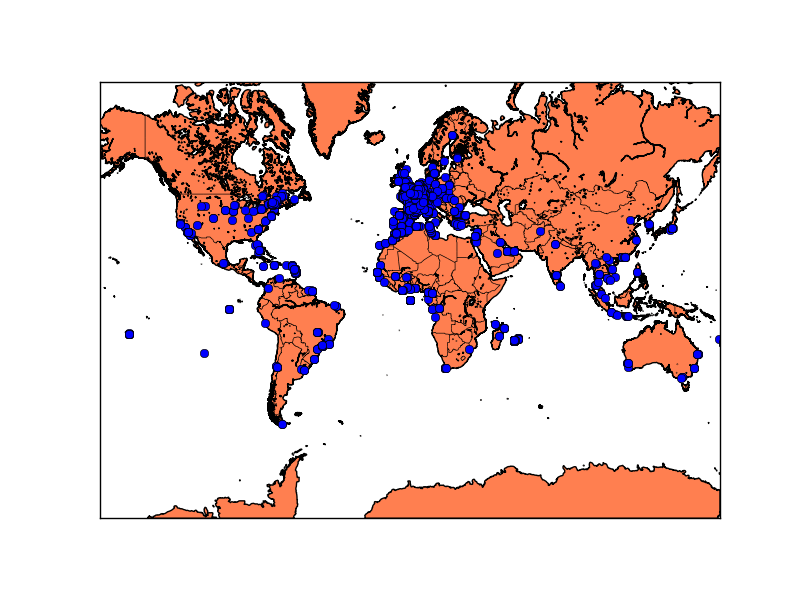
This Europe map shows that this event is mainly followed in France and little in the rest of Europe. The fact that we tracked the posts written in French contributes to this result.

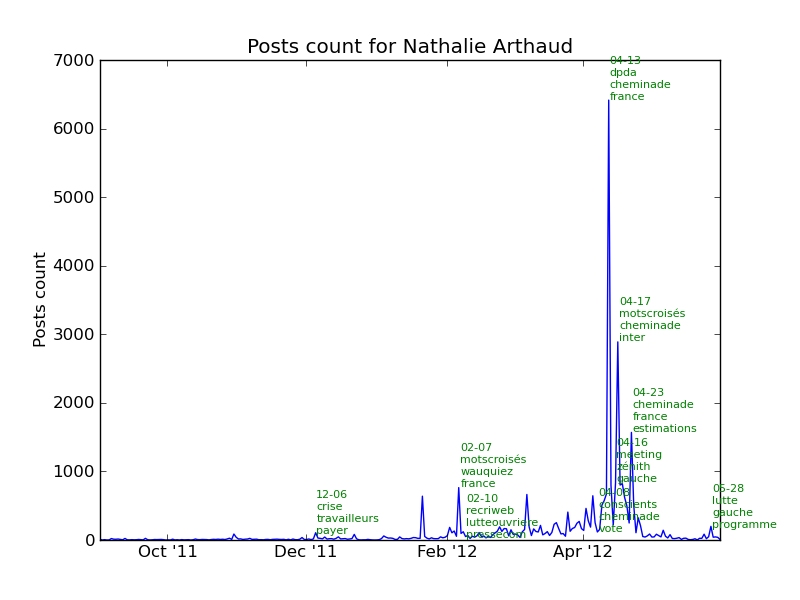
Next, we looked at what other candidates an author talks about when his most talked candidate is person A. Below, you can see that if an author most talked candidate is Nathalie Arthaud then that author also talks about François Hollande, Nicolas Sarkozy and Marine Le Pen.
In 11 on 17 cases, the most talked candidate is Nicolas Sarkozy. Reciprocity is not a rule. When an author talks about Nicolas Hulot, he also talks about Eva Joly (2nd most). The opposite is not true.
- Nathalie Arthaud
- François Hollande – 19.2%
- Nicolas Sarkozy – 18.8%
- Marine Le Pen – 11.1%
- Philippe Poutou – 11.1%
- Eva Joly – 9.2%
- Martine Aubry
- François Hollande – 31.4%
- Nicolas Sarkozy – 19.5%
- Ségolène Royal – 9.2%
- Arnaud Montebourg – 8.6%
- Marine Le Pen – 7.8%
- Jean-Michel Baylet
- François Hollande – 21.9%
- Nicolas Sarkozy – 19.7%
- Marine Le Pen – 10.1%
- Arnaud Montebourg – 7.9%
- Eva Joly – 7.5%
- François Bayrou
- François Hollande – 24.2%
- Nicolas Sarkozy – 23.9%
- Marine Le Pen – 10.2%
- Jean-Luc Mélenchon – 8.2%
- Eva Joly – 6.6%
- Christine Boutin
- Nicolas Sarkozy – 31.5%
- François Hollande – 24.8%
- Marine Le Pen – 11.2%
- Ségolène Royal – 6.7%
- Eva Joly – 4.9%
- Nicolas Dupont Aignan
- Nicolas Sarkozy – 24.1%
- François Hollande – 23.1%
- Marine Le Pen – 14.9%
- Jean-Luc Mélenchon – 8.6%
- Eva Joly – 8.3%
- François Hollande
- Nicolas Sarkozy – 32.8%
- Marine Le Pen – 13.8%
- Jean-Luc Mélenchon – 7.6%
- François Bayrou – 7.5%
- Eva Joly – 6.9%
- Nicolas Hulot
- Nicolas Sarkozy – 31.6%
- Eva Joly – 18.3%
- François Hollande – 10.7%
- Marine Le Pen – 10.2%
- Ségolène Royal – 8.9%
- Eva Joly
- Nicolas Sarkozy – 27.4%
- Marine Le Pen – 15.2%
- François Hollande – 14.5%
- Jean-Luc Mélenchon – 7.6%
- François Bayrou – 5.8%
- Marine Le Pen
- Nicolas Sarkozy – 33.6%
- François Hollande – 19.8%
- Jean-Luc Mélenchon – 14.0%
- Eva Joly – 6.1%
- Ségolène Royal – 5.5%
- Jean-Luc Mélenchon
- Nicolas Sarkozy – 23.3%
- François Hollande – 15.9%
- Marine Le Pen – 14.7%
- François Bayrou – 8.8%
- Eva Joly – 6.4%
- Arnaud Montebourg
- Nicolas Sarkozy – 25.2%
- François Hollande – 15.8%
- Ségolène Royal – 8.1%
- Martine Aubry – 7.9%
- Manuel Valls – 6.5%
- Philippe Poutou
- Nicolas Sarkozy – 32.0%
- François Hollande – 20.6%
- Marine Le Pen – 12.1%
- Eva Joly – 6.8%
- Ségolène Royal – 6.4%
- Ségolène Royal
- Nicolas Sarkozy – 32.4%
- François Hollande – 19.2%
- Marine Le Pen – 9.4%
- Martine Aubry – 6.0%
- Eva Joly – 5.2%
- Nicolas Sarkozy
- François Hollande – 21.4%
- Marine Le Pen – 13.8%
- François Bayrou – 9.2%
- Jean-Luc Mélenchon – 8.8%
- Eva Joly – 7.9%
- Manuel Valls
- François Hollande – 24.4%
- Nicolas Sarkozy – 19.1%
- Martine Aubry – 8.8%
- Arnaud Montebourg – 7.9%
- Marine Le Pen – 7.6%
- Dominique Villepin
- Nicolas Sarkozy – 18.9%
- François Hollande – 16.4%
- François Bayrou – 11.3%
- Marine Le Pen – 9.7%
- Eva Joly – 6.6%
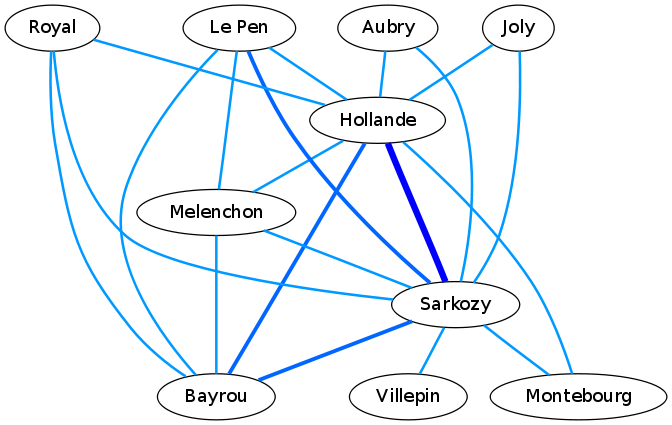
The following graph shows connections between candidates based on number of identical words used when posts are referring to them. Wider the vertex is, more words are in common. An obvious link is Hollande – Sarkozy. Bayrou being in the center politically has two strong links: with Sarkozy and with Hollande. This is also expected. We notice another strong link between Le Pen and Sarkozy. This link makes sense based on some subjects discussed by both candidates.
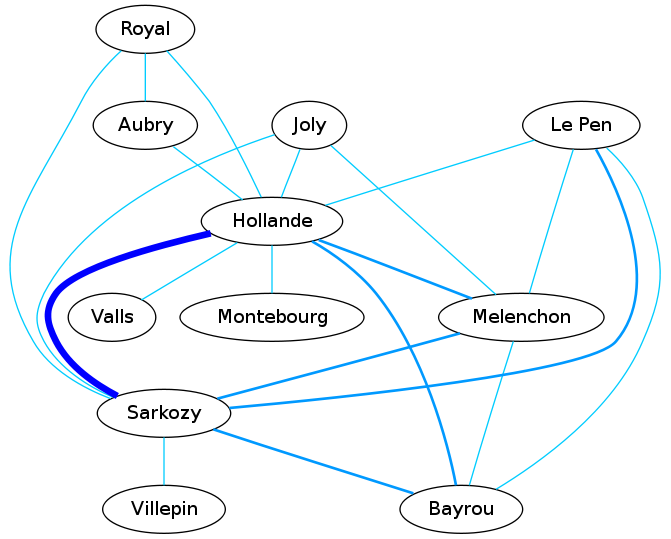
Next is a similar chart but based on posts referring multiple candidates. What is interesting here are the links going across political boundaries. Mélenchon has two major links: one with a candidate on the left and one with a candidate on the right. Joly has two links with candidates on the left and one with a candidate on the right. It makes sense when you know that Joly is more on the left on the political spectrum.
Let’s look at the major events for each candidate. As we are tracking the number of posts for each candidate, we can find out the events and what those were about by looking at the most used words in the posts.
The next chart shows that about 22500 posts talked about François Bayrou on March 9th. Looking at the most used words, we can see that the candidate was participating to a TV show called “Des paroles et des actes” also abbreviated “dpda”. “soir” means evening and the TV show takes place in the evening.

See the section events in the annexes for the complete list of events for each candidate.
Next is a bar chart showing the number of authors mainly talking about a candidate (80% or more of the posts only related that candidate). We notice a strong presence online of authors mainly talking about François Hollande. We notice 2 others strong presence online: Marine Le Pen and Ségolène Royal.

Annexes
Events







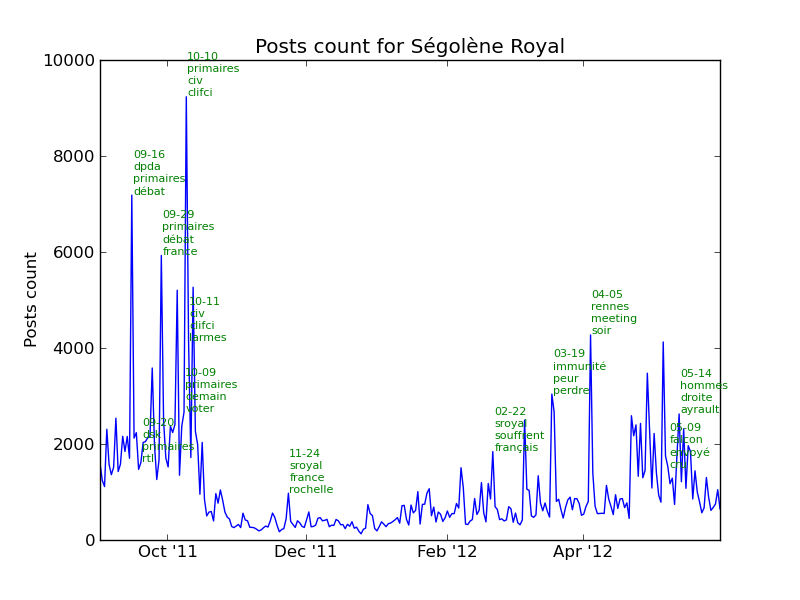
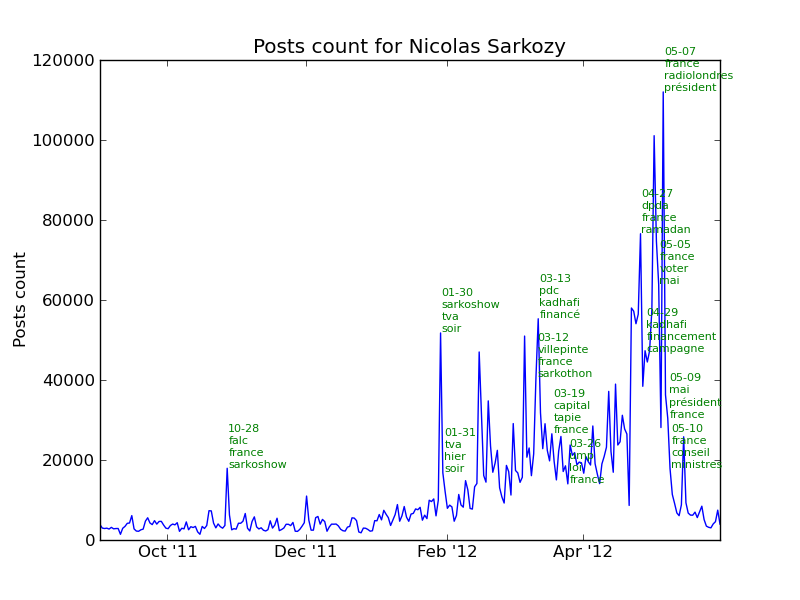
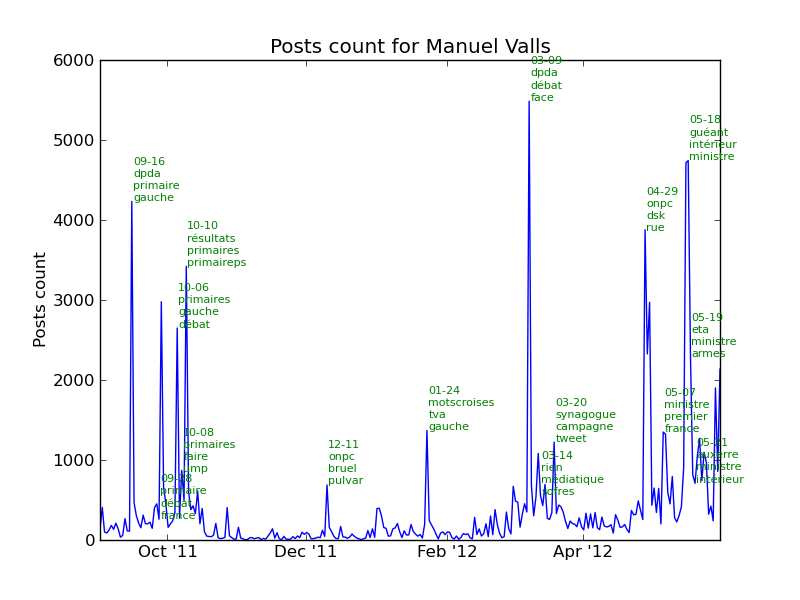

Comments
Wow, amazing article. Very interesting, we did something similar to this for the elections in Pakistan.
Good job ! it inspires us for further developments for our system because we are also concerned by French presidential campaign, Twitter analytics, and Twitter archiving… and python programming !
Very interesting post. Going through this I get not only how to implement thing in Python, but also about software architecture. Thank so much.
Comments are closed.